Kafka服务使用说明
1. 简介
Kafka MQ是一个高吞吐量分布式消息系统。是由linkedin开发并开源的消息中间件。 kafka的数据只会顺序append,数据的删除策略是累积到一定程度或者超过一定时间再删除。 Kafka另一个独特的地方是将消费者信息保存在客户端而不是MQ服务器,这样服务器就不用记录消息的投递过程,每个客户端都自己知道自己下一次应该从什么地方什么位置读取消息,消息的投递过程也是采用客户端主动pull的模型,这样大大减轻了服务器的负担。 kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。设计侧重高吞吐量,用于好友动态,相关性统计,排行统计,访问频率控制,批处理等系统。传统的离线分析方案是使用日志文件记录数据,然后集中批量处理分析。
2. 版本
当前订阅的Kafka服务的版本:0.10.1.0
3. 订阅及使用说明
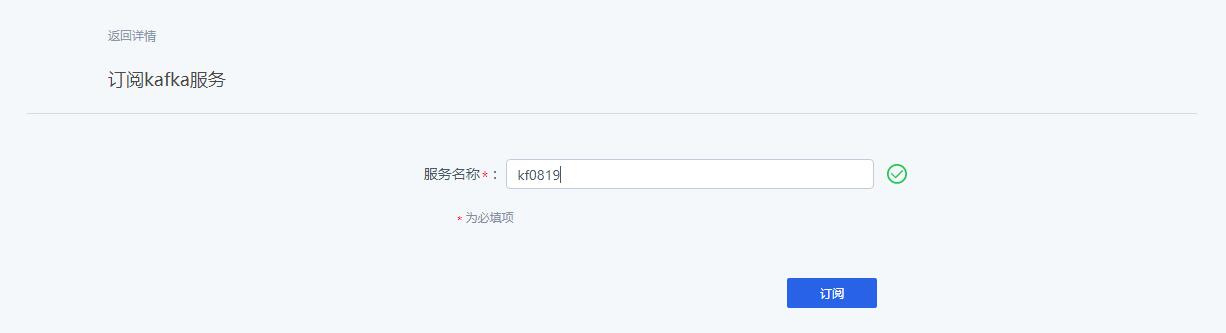
1 参考寄云应用开发与数据分析平台使用手册完成Kafka服务的订阅,订阅过程中,可以输入Kafka服务的服务名称。
2 Kafka服务详情
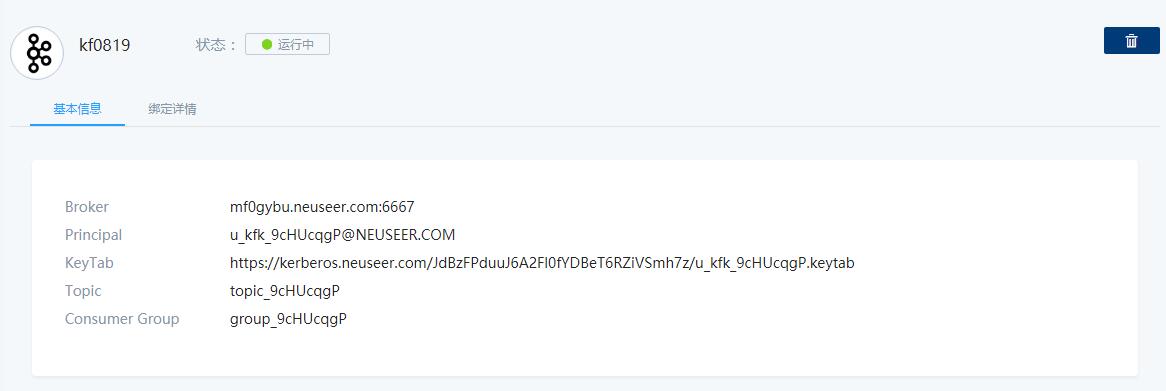
订阅完成后,在服务详情页面将给出如下服务参数:
Broker:mf0gybu.neuseer.com:6667
Principal:u_kfk_9cHUcqgP@NEUSEER.COM
KeyTab:https://kerberos.neuseer.com/JdBzFPduuJ6A2Fl0fYDBeT6RZiVSmh7z/u_kfk_9cHUcqgP.keytab
Topic:topic_9cHUcqgP
Consumer Group:group_9cHUcqgP
3 Kafka服务绑定
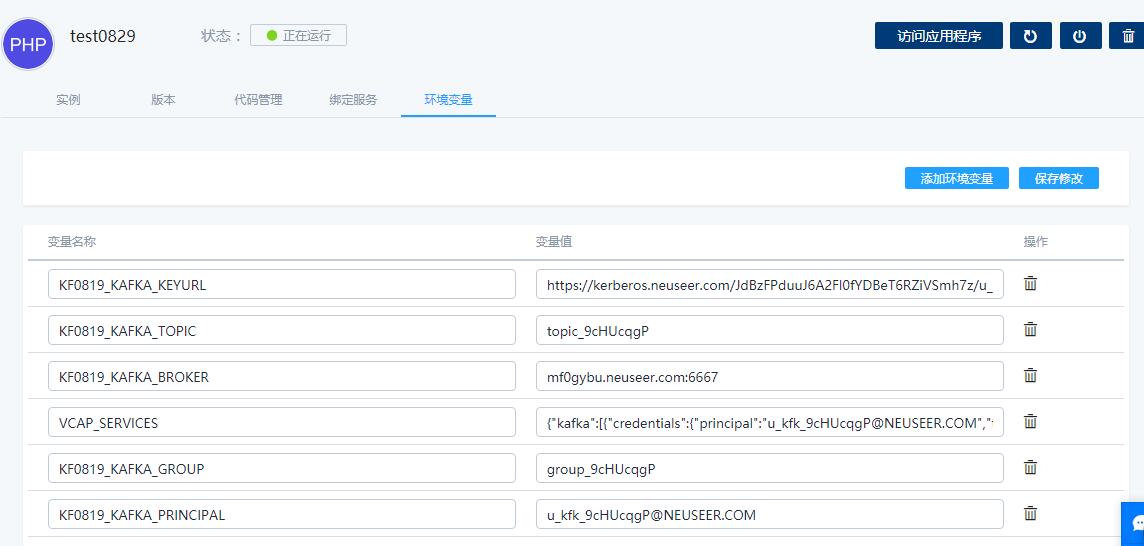
寄云应用开发与数据分析平台能够提供应用绑定服务的能力,在完成绑定后,将把服务相关的环境变量注入到应用实例中去(绑定的详细操作过程,请参见使用手册),在应用开发的过程中,直接使用这些环境变量即可实现对Kafka服务的访问和操作。
绑定后注入应用的环境变量包括:
XXXX(服务名)_ KAFKA _BROKER: Kafka服务Broker的地址和端口
XXXX(服务名)_ KAFKA _KEYURL: Kafka服务认证文件的下载地址
XXXX(服务名)_ KAFKA _ TOPIC: Kafka服务的主题
XXXX(服务名)_ KAFKA _ GROUP: Kafka服务消费者组id
XXXX(服务名)_ KAFKA _ PRINCIPAL: Kafka服务认证的PRINCIPAL参数
VCAP_SERVICES: Kafka服务连接信息
4 Kafka服务使用
目前我们提供的Kafka服务采用SASL/Kerberos认证方式,在使用服务时需要进行相关的配置。
使用Kafka console命令产生和消费消息
使用服务详情中Kafka服务认证文件的下载地址下载keytab文件,并将其放置于Kafka的config目录中,同时修改其权限,让运行Kafka console命令的用户可以访问该文件。
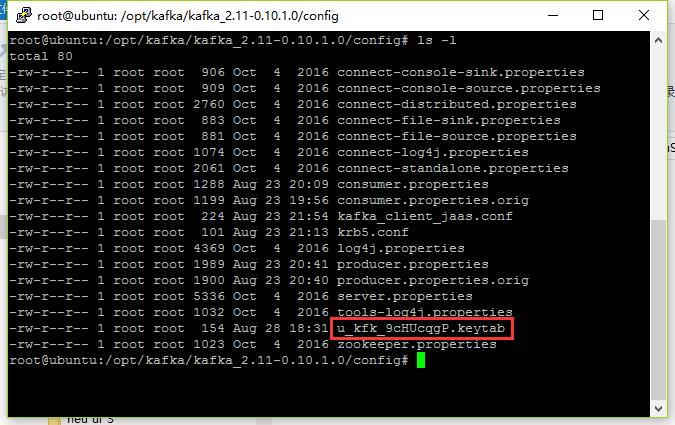
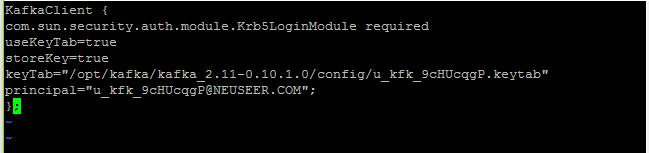
在Kafka的config目录中,创建或编辑kafka_client_jaas.conf文件:
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab=keytab文件的路径(如"/opt/kafka/kafka_2.11-0.10.1.0/config/u_kfk_9cHUcqgP.keytab")
principal=PRINCIPAL参数(如"u_kfk_9cHUcqgP@NEUSEER.COM");
};
在Kafka的config目录中,创建或编辑krb5.conf文件:
[domain_realm]
.neuseer.com = NEUSEER.COM
[realms]
NEUSEER.COM = {
kdc = kerberos.neuseer.com
}

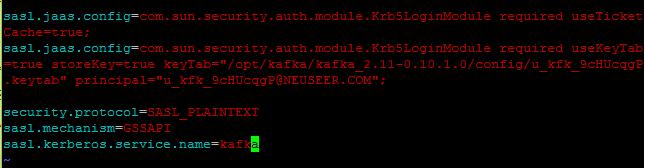
在Kafka的config目录中,编辑producer.properties和consumer.properties文件,增加以下内容:
sasl.jaas.config=com.sun.security.auth.module.Krb5LoginModule required useTicketCache=true;
sasl.jaas.config=com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true storeKey=true keyTab= keytab文件的路径(如"/opt/kafka/kafka_2.11-0.10.1.0/config/u_kfk_9cHUcqgP.keytab") principal= PRINCIPAL参数(如"u_kfk_9cHUcqgP@NEUSEER.COM");
security.protocol=SASL_PLAINTEXT
sasl.mechanism=GSSAPI
sasl.kerberos.service.name=kafka
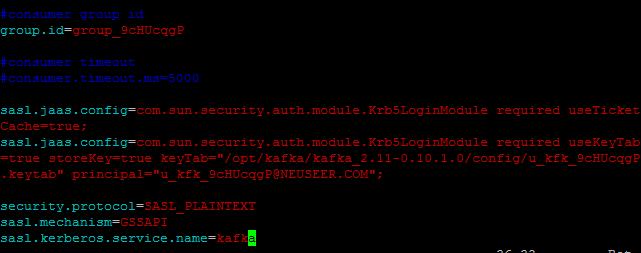
除此之外,还要编辑consumer.properties文件中的group.id参数:
group.id= 服务详情中的Consumer Group(如group_9cHUcqgP)
在运行Kafka console命令的远程终端上配置环境变量:
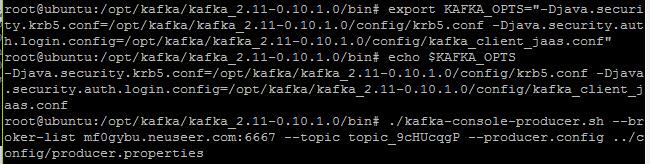
export KAFKA_OPTS="-Djava.security.krb5.conf=krb5文件地址(如/opt/kafka/kafka_2.11-0.10.1.0/config/krb5.conf) -Djava.security.auth.login.config= kafka_client_jaas 文件地址(如/opt/kafka/kafka_2.11-0.10.1.0/config/kafka_client_jaas.conf)"
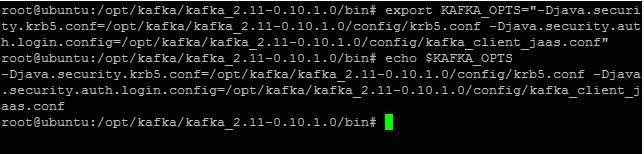
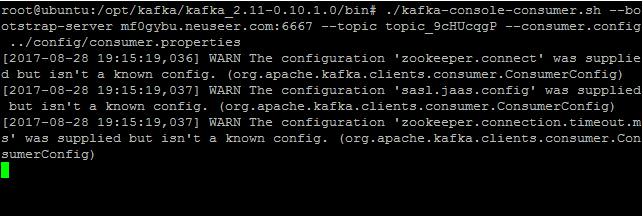
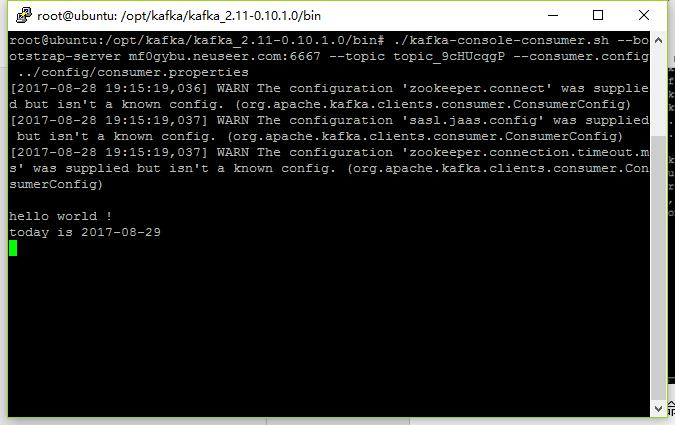
在Kafka的bin目录中,运行以下命令启动Consumer:
./kafka-console-consumer.sh --bootstrap-server Broker的地址和端口(如mf0gybu.neuseer.com:6667) --topic 主题(如topic_9cHUcqgP) --consumer.config ../config/consumer.properties
切换到其它远程终端上,在Kafka的bin目录中,运行以下命令启动producer命令:
./kafka-console-producer.sh --broker-list Broker的地址和端口(如mf0gybu.neuseer.com:6667) --topic 主题(如topic_9cHUcqgP) --producer.config ../config/producer.properties
在producer命令远程终端上输入消息:
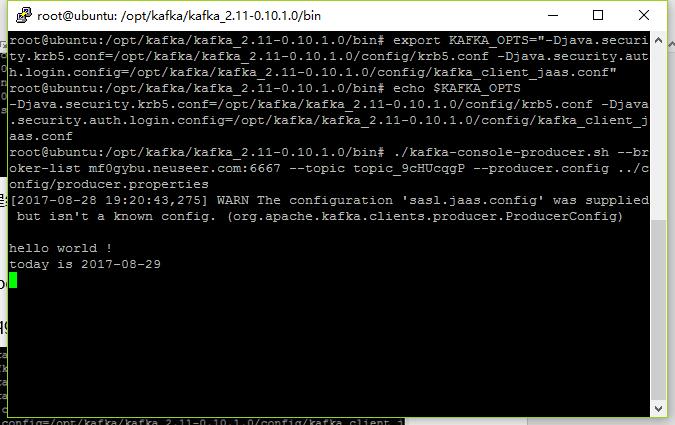
在Consumer命令远程终端上可以看到收到的消息:
通过Java编程使用服务
创建kafka_client_jaas.conf文件、krb5.conf文件,文件内容如上节所示。同样需要下载keytab文件放在该目录下。
java类中设置系统环境变量:
java.security.auth.login.config java.security.krb5.conf
System.setProperty("java.security.auth.login.config", "kafka_client_jaas.conf");
System.setProperty("java.security.krb5.conf","krb5.conf");
properties设置连接方式、连接参数
spring.kafka.properties.security.protocol=SASL_PLAINTEXT
spring.kafka.properties.sasl.mechanism=GSSAPI
spring.kafka.properties.sasl.mechanism.inter.broker.protocol=GSSAPI
spring.kafka.properties.sasl.kerberos.service.name=kafka
设置环境变量
spring_kafka_bootstrapServers= Broker的地址和端口(如hdp-master-r0h7l4.neucloud-bd.org:6667)
spring_kafka_consumer_groupId=Consumer Group(如group-test)
spring_kafka_template_defaultTopic=主题(如topic-test)
producer代码示例如下:
package com.ge.predix.solsvc.fdh.handler;
import java.util.List;
import java.util.Map;
import org.apache.http.Header;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import com.ge.predix.entity.putfielddata.PutFieldDataCriteria;
import com.ge.predix.entity.putfielddata.PutFieldDataRequest;
import com.ge.predix.entity.putfielddata.PutFieldDataResult;
import com.ge.predix.entity.timeseries.datapoints.ingestionrequest.Body;
import com.ge.predix.entity.timeseries.datapoints.ingestionrequest.DatapointsIngestion;
@Component(value = "kafkaPutFieldDataHandler")
public class KafkaPutDataHandler implements PutDataHandler
{
@Autowired
private KafkaTemplate<Object, Object> template;
@Override
public PutFieldDataResult putData(PutFieldDataRequest request, Map<Integer, Object> modelLookupMap,
List<Header> headers, String httpMethod) {
System.setProperty("java.security.auth.login.config", "kafka_client_jaas.conf");
System.setProperty("java.security.krb5.conf","krb5.conf");
for (PutFieldDataCriteria criteria:request.getPutFieldDataCriteria()) {
if (criteria.getFieldData().getData() instanceof DatapointsIngestion) {
processDatapointsIngestion(criteria);
}
}
PutFieldDataResult result = new PutFieldDataResult();
result.getErrorEvent().add("Data Sent to kafka");
return result;
}
@SuppressWarnings("u· checked")
private void processDatapointsIngestion(PutFieldDataCriteria putFieldDataCriteria)
{
DatapointsIngestion datapointsIngestion = (DatapointsIngestion) putFieldDataCriteria.getFieldData().getData();
List<Body> bodyList = datapointsIngestion.getBody();
for (Body body:bodyList) {
String[] name = body.getName().split(":");
String assetId = name[0];
String nodeName = name[1];
List<Object> datapoints=body.getDatapoints();
List<Object> data;
for (Object datapoint:datapoints) {
data = (List<Object>) datapoint;
this.template.sendDefault(data.get(0).toString()+','+assetId+','+nodeName+','+data.get(1).toString());
}
}
}
}
通过shell命令kafkacat客户端使用服务
通过kafkacat命令客户端可以使用在NeuSeer平台上订阅的Kafka服务,以下为在CentOS环境中使用kafkacat命令产生和订阅消息的配置示例。
编译及安装kafkacat:
依次运行以下命令,完成kafkacat下载、编译和安装:
yum -y install cmake gcc gcc-c++ git
yum -y install zlib-devel openssl-devel cyrus-sasl-devel lz4-devel
git clone https://github.com/edenhill/kafkacat.git
cd kafkacat && ./bootstrap.sh && make install
依赖包安装:
针对 Kerberos 认证需要安装以下依赖包并进行针对性的配置:
yum -y install krb5-workstation cyrus-sasl-gssapi
cat > /etc/krb5.conf << EOF
[libdefaults]
dns_lookup_kdc = false
rdns = false
[domain_realm]
.neuseer.com = NEUSEER.COM
[realms]
NEUSEER.COM = {
kdc = kerberos.neuseer.com
}
EOF
将认证使用的keytab文件上载到kafkacat所在的目录中。
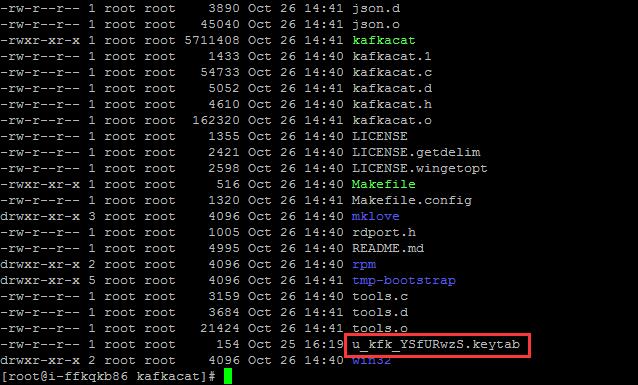
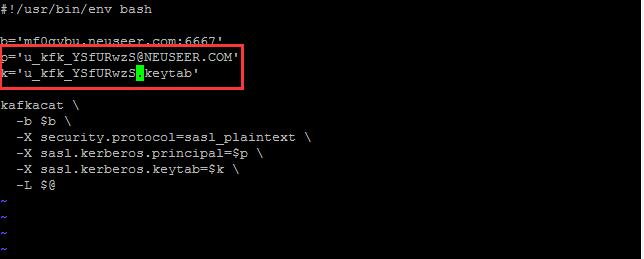
创建运行命令脚本:
获取基本信息命令脚本-metalist.sh:
#!/usr/bin/env bash
b='mf0gybu.neuseer.com:6667'
p='u_kfk_xxxxxxxx@NEUSEER.COM'
k='u_kfk_xxxxxxxx.keytab'
kafkacat \
-b $b \
-X security.protocol=sasl_plaintext \
-X sasl.kerberos.principal=$p \
-X sasl.kerberos.keytab=$k \
-L $@
将其中的xxxxxxxx修改为对应的值。
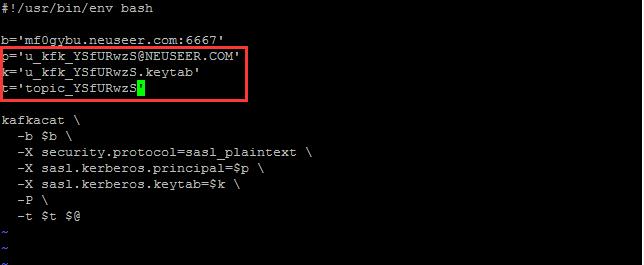
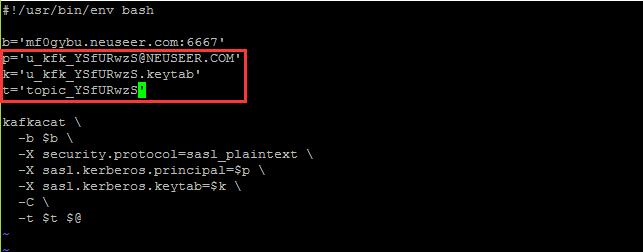
发布消息命令脚本- producer.sh:
#!/usr/bin/env bash
b='mf0gybu.neuseer.com:6667'
p='u_kfk_xxxxxxxx@NEUSEER.COM'
k='u_kfk_xxxxxxxx.keytab'
t='topic_xxxxxxxx'
kafkacat \
-b $b \
-X security.protocol=sasl_plaintext \
-X sasl.kerberos.principal=$p \
-X sasl.kerberos.keytab=$k \
-P \
-t $t $@
将其中的xxxxxxxx修改为对应的值。
订阅消息命令脚本- consumer.sh:
#!/usr/bin/env bash
b='mf0gybu.neuseer.com:6667'
p='u_kfk_xxxxxxxx@NEUSEER.COM'
k='u_kfk_xxxxxxxx.keytab'
t='topic_xxxxxxxx'
kafkacat \
-b $b \
-X security.protocol=sasl_plaintext \
-X sasl.kerberos.principal=$p \
-X sasl.kerberos.keytab=$k \
-C \
-t $t $@
将其中的xxxxxxxx修改为对应的值。
然后给这些文件增加执行权限
chmod +x metalist.sh producer.sh consumer.sh
运行脚本命令使用Kafka服务:
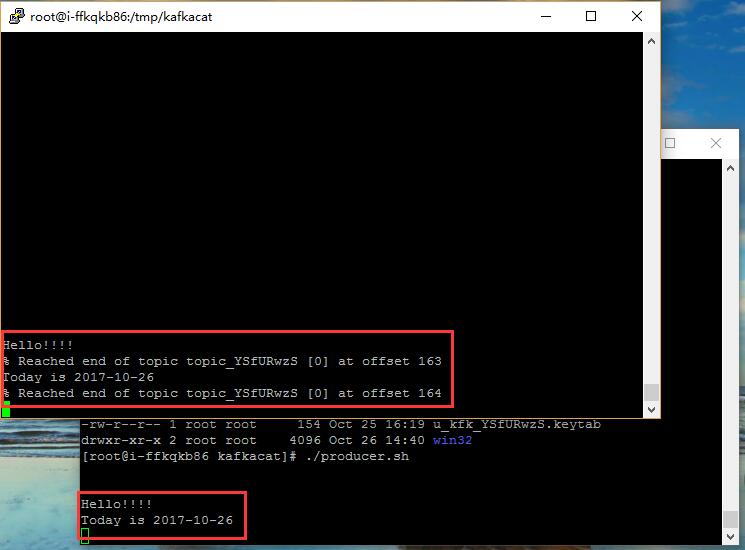
运行consumer.sh命令订阅Kafka服务的相关Topic,在kafkacat所在的目录运行一下命令:
./consumer.sh
在其他的远程窗口中,运行producer.sh命令将消息发布到Kafka服务的相关Topic中,在kafkacat所在的目录运行一下命令:
./producer.sh
之后我们在运行producer.sh命令的远程窗口发布消息,即可在运行consumer.sh命令的远程窗口看到这些信息。
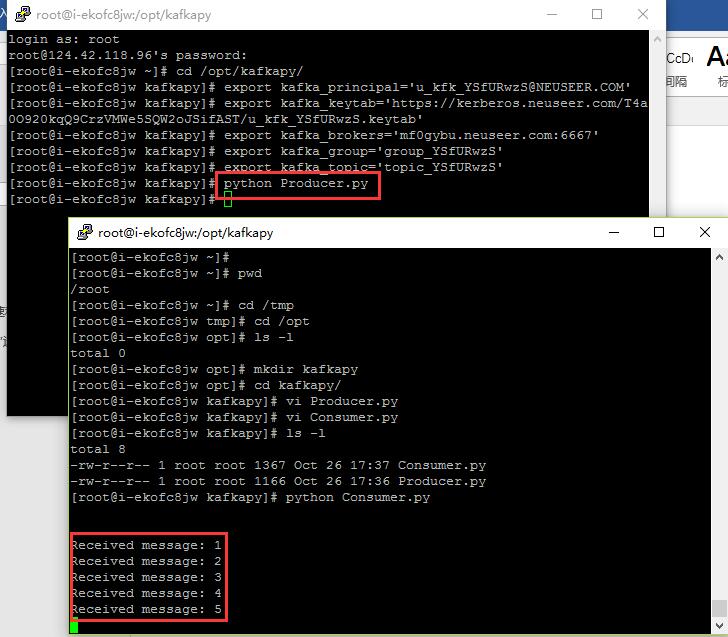
通过Python编程使用服务:
通过Python编程可以使用在NeuSeer平台上订阅的Kafka服务,以下为在CentOS环境中使用Python编程产生和订阅消息的配置及代码示例。
依赖包安装:
yum -y install epel-release
yum -y install gcc python-devel librdkafka-devel
pip install confluent-kafka
针对 Kerberos 认证需要安装以下依赖包并进行针对性的配置:
yum -y install krb5-workstation cyrus-sasl-gssapi
cat > /etc/krb5.conf << EOF
[libdefaults]
dns_lookup_kdc = false
rdns = false
[domain_realm]
.neuseer.com = NEUSEER.COM
[realms]
NEUSEER.COM = {
kdc = kerberos.neuseer.com
}
EOF
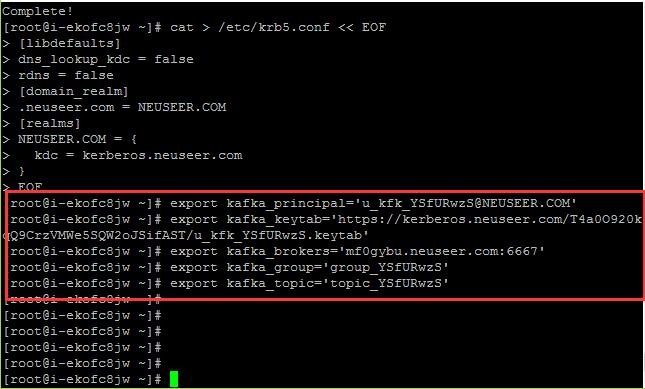
设置系统环境变量:
设置以下系统环境变量
export kafka_principal='u_kfk_xxxxxxxx@NEUSEER.COM'
export kafka_keytab='https://kerberos.neuseer.com/xxx/xxx.keytab'
export kafka_brokers='mf0gybu.neuseer.com:6667'
export kafka_group='group_xxxxxxxx'
export kafka_topic='topic_xxxxxxxx'
将其中的xxxxxxxx修改为对应的值。
Producer和Consumer示例代码
Producer.py:
#!/usr/bin/env python
#
# https://docs.confluent.io/current/clients/confluent-kafka-python/
#
import os
import tempfile
from confluent_kafka import Producer
def get_keytab(url):
try:
# python 3
from urllib.request import urlopen
except ImportError:
# python 2
from urllib2 import urlopen
fd, filename= tempfile.mkstemp()
r = urlopen(url)
with os.fdopen(fd, "w+b") as f:
while True:
chunk = r.read(4096)
if not chunk:
break
f.write(chunk)
return filename
def producer(data):
env_list = [
'kafka_principal',
'kafka_keytab',
'kafka_brokers',
'kafka_topic',
]
for env in env_list:
envv = os.environ.get(env)
if envv:
globals()[env] = envv
else:
raise Exception("missing env '{}'".format(env))
p = Producer({
'security.protocol': 'sasl_plaintext',
'sasl.kerberos.principal': kafka_principal,
'sasl.kerberos.keytab': get_keytab(kafka_keytab),
'bootstrap.servers': kafka_brokers,
})
for d in data:
p.produce(kafka_topic, d.encode('utf-8'))
p.flush()
if __name__ == "__main__":
data = ['1', '2', '3', '4', '5']
producer(data)
Consumer.py:
#!/usr/bin/env python
#
# https://docs.confluent.io/current/clients/confluent-kafka-python/
#
import os
import tempfile
from confluent_kafka import Consumer, KafkaError
def get_keytab(url):
try:
# python 3
from urllib.request import urlopen
except ImportError:
# python 2
from urllib2 import urlopen
fd, filename = tempfile.mkstemp()
r = urlopen(url)
with os.fdopen(fd, "w+b") as f:
while True:
chunk = r.read(4096)
if not chunk:
break
f.write(chunk)
return filename
def consumer():
env_list = [
'kafka_principal',
'kafka_keytab',
'kafka_brokers',
'kafka_group',
'kafka_topic',
]
for env in env_list:
envv = os.environ.get(env)
if envv:
globals()[env] = envv
else:
raise Exception("missing env '{}'".format(env))
c = Consumer({
'security.protocol': 'sasl_plaintext',
'sasl.kerberos.principal': kafka_principal,
'sasl.kerberos.keytab': get_keytab(kafka_keytab),
'bootstrap.servers': kafka_brokers,
'group.id': kafka_group,
})
c.subscribe([kafka_topic])
while True:
msg = c.poll()
if not msg.error():
print('Received message: %s' % msg.value().decode('utf-8'))
elif msg.error().code() != KafkaError._PARTITION_EOF:
print(msg.error())
break
c.close()
if __name__ == "__main__":
consumer()
在不同的远程窗口的代码文件目录中先后运行以下命令,即可在运行Consumer.py代码的窗口中收到相关消息。
python Consumer.py
python Producer.py