Spark服务使用说明
1. 简介:
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。 Spark拥有Hadoop MapReduce所具有的优点;不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。 Spark与Hadoop相比较,但是两者之间还存在一些不同之处,比如 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
2. 版本:
当前订阅的Spark大数据服务的版本:1.6
3. 订阅及使用说明:
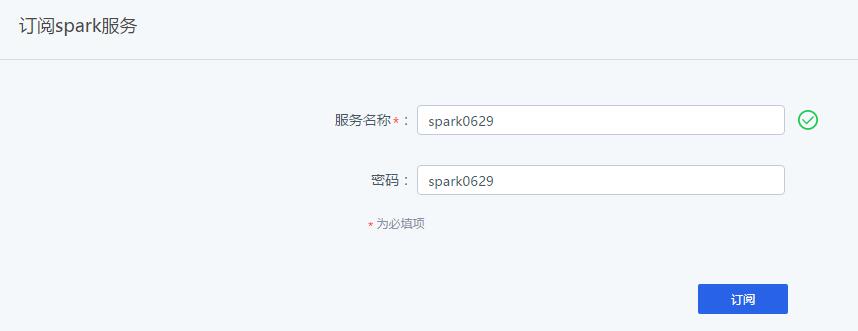
1 参考寄云应用开发与数据分析平台使用手册完成Spark大数据服务的订阅,订阅过程中,可以输入大数据服务的名称及访问密码。
2 目前平台提供通过Zeppelin的Web界面提交各种分析任务代码,在Spark处理完成后,将结果呈现出来。在Spark大数据服务订阅成功后,进入服务详情页面,选择右上方的管理服务按钮访问服务。

3 进入Zeppelin界面后,选择右上角的登录按钮,使用上一步获得的用户名和密码进行登录,即可进入到Zeppelin工作界面。

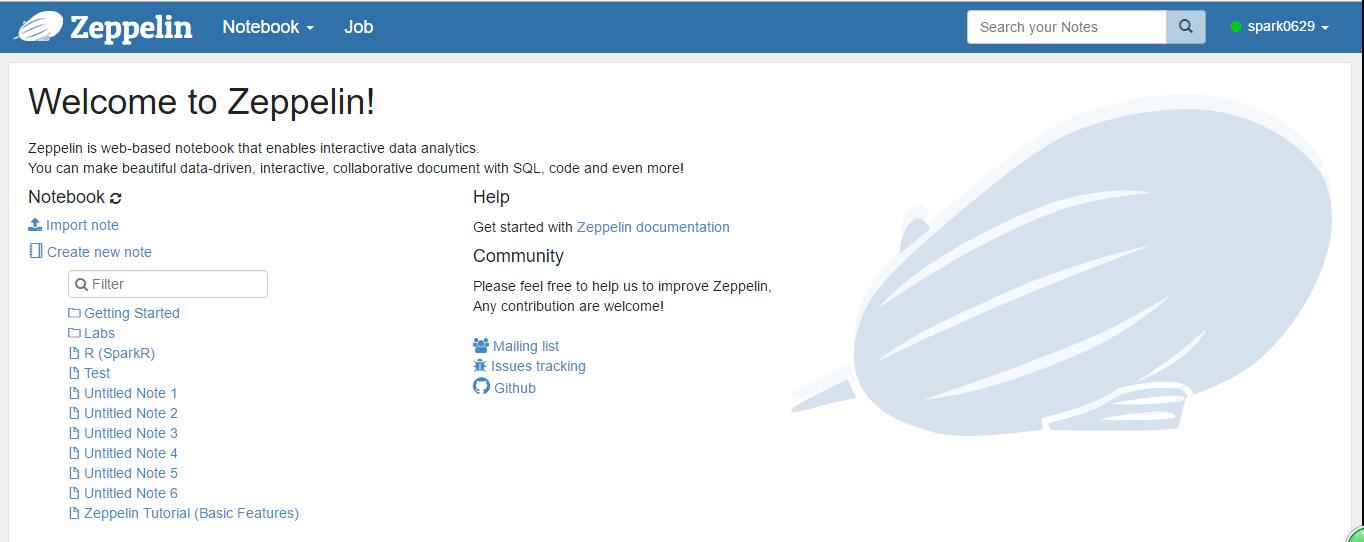 4. 登录zepplin后,选择“Create new note”,填写“note name”,点“Create note”。
4. 登录zepplin后,选择“Create new note”,填写“note name”,点“Create note”。
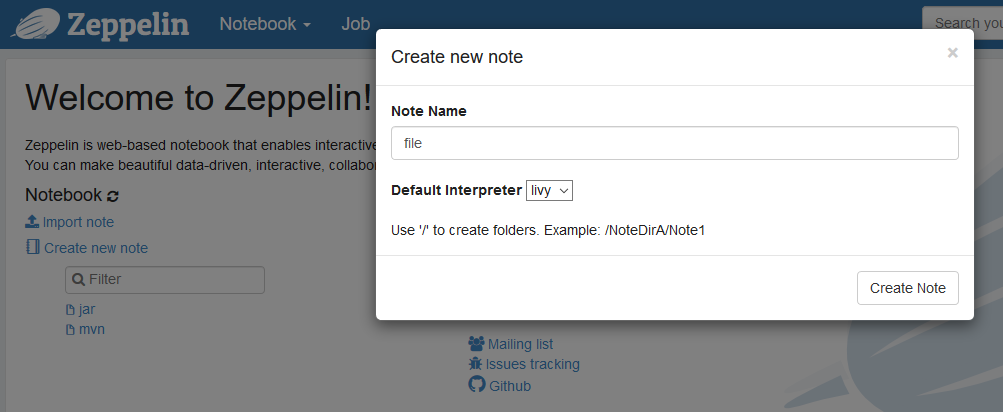 5. 创建成功后,选择右上角的“管理依赖”,管理依赖可以上传files或jars到hdfs目录,上传方式参见HDFS服务使用说明。可以通过Maven仓库指定依赖库的group ID、artifact ID以及version来指定具体的依赖
5. 创建成功后,选择右上角的“管理依赖”,管理依赖可以上传files或jars到hdfs目录,上传方式参见HDFS服务使用说明。可以通过Maven仓库指定依赖库的group ID、artifact ID以及version来指定具体的依赖
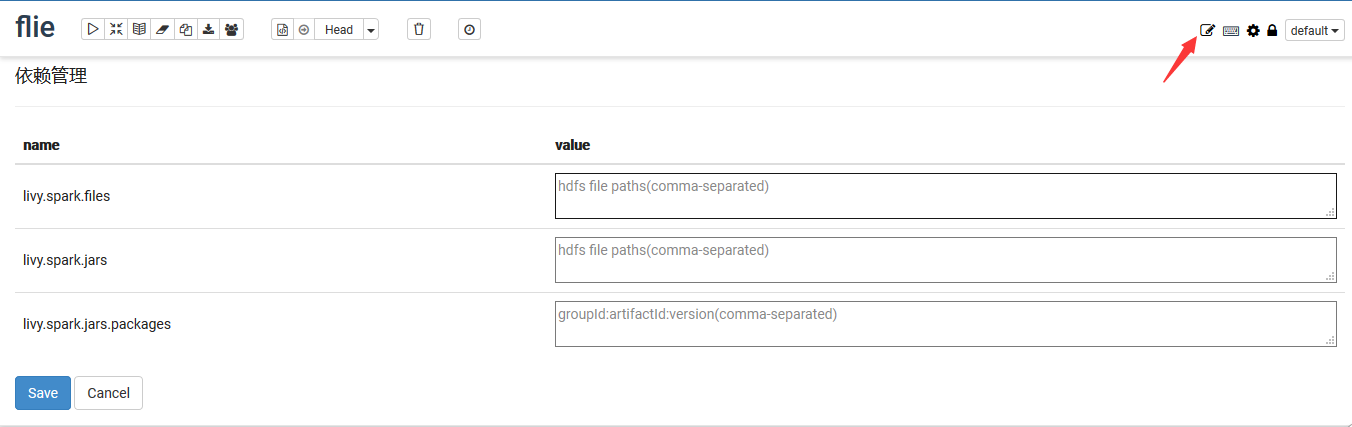 6. 上传文件成功后将HDFS的路径填写到“livy.spark.files”中,点“Save”,执行方框示例代码后显示test.json.
6. 上传文件成功后将HDFS的路径填写到“livy.spark.files”中,点“Save”,执行方框示例代码后显示test.json.
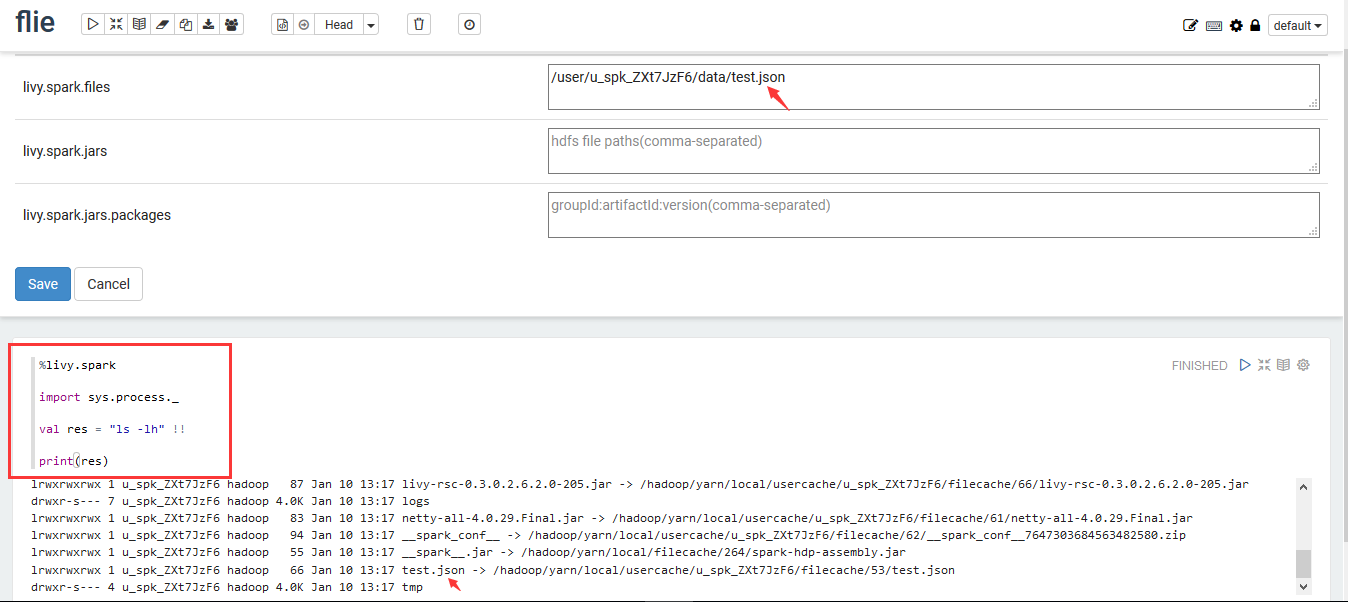 7. 同样执行第4步操作,上传jars成功后将HDFS的路径填写到“livy.spark.jars”中,点“Save”,执行方框示例代码后结果如下。
7. 同样执行第4步操作,上传jars成功后将HDFS的路径填写到“livy.spark.jars”中,点“Save”,执行方框示例代码后结果如下。
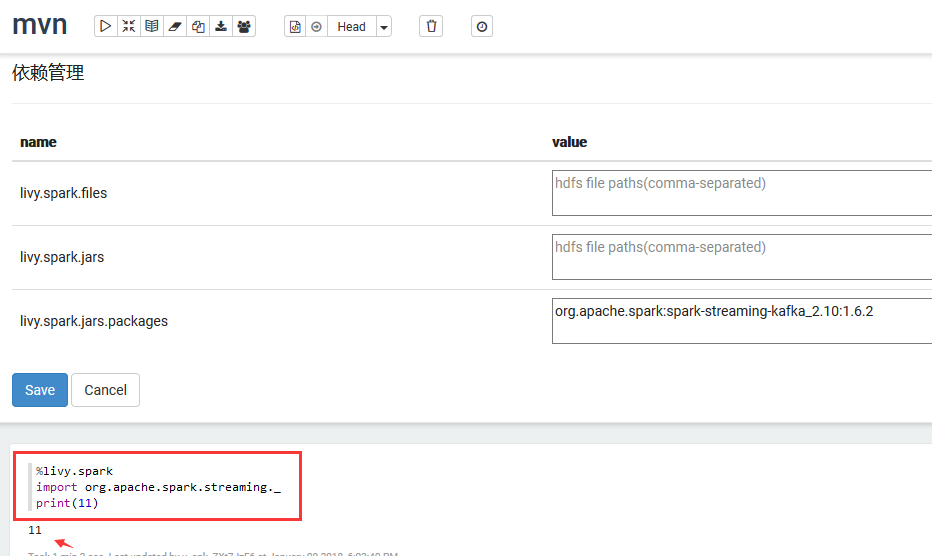
 8. 通过Maven仓库指定依赖库的group ID、artifact ID以及version来指定具体的依赖方式登录http://mvnrepository.com,搜索如kafka,
8. 通过Maven仓库指定依赖库的group ID、artifact ID以及version来指定具体的依赖方式登录http://mvnrepository.com,搜索如kafka,
找到如下页面:
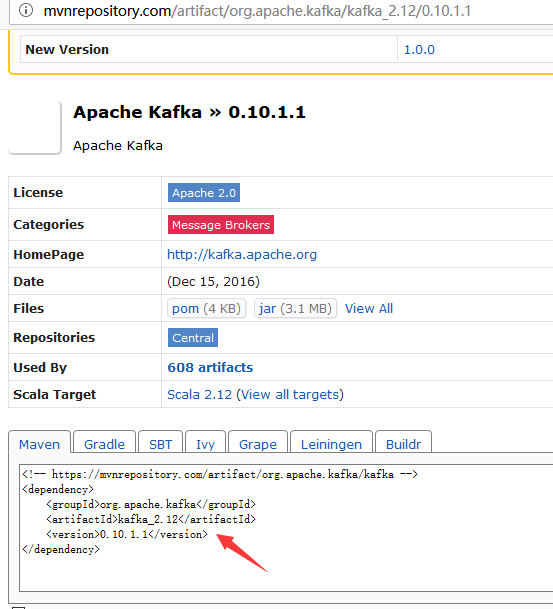
执行第4步操作后在“livy.spark.jars.packages”中,填写“org.apache.spark:spark-streaming-kafka_2.10:1.6.2”点“Save”,执行方框示例代码后结果如下。